8. DATA ANALYSIS
8.1 INTRODUCTION
The graphical analysis of data, described in chapter 7, is most useful for communicating results in reports and for gaining intuitive understanding of phenomena. However, when accurate results are required, analytic methods are preferred over graphical methods. This chapter will introduce some of these methods. Advanced texts may be consulted for additional details.
The purpose of data analysis is to use all of the data to calculate one or more results. This is usually done by averaging large amounts of data. The averaging method must be carefully chosen so that it actually uses all of the data in a consistent way. Some averaging methods which "look good" on superficial analysis, may actually cancel out some of the data, or may be emphasizing the least accurate data. The methods described below avoid such pitfalls and give results which are the best obtainable for the data used.
Implicit in all these methods is the assumption that the individual data values have Gaussian distributions. If there is good reason to believe that the distributions are not Gaussian, modified methods are required.
The student should not consider data analysis as something which can be "left for later," to be ignored until the laboratory work is finished. Good experimental strategy requires that the experiment be "thought through" even before data is taken, so that the data-taking procedure will produce sufficient data, of adequate quality, and with sufficient range, for the intended method of analysis. Thus concern with the methods of data analysis will permeate the entire experimental process, from experimental design, through data collecting, to the final calculations.
Data analysis (which includes error analysis) can show which quantities must be measured most precisely. It can show that some experimental designs are unsuitable for good measurements of some quantities, suggesting a search for better designs.
The student who leaves the analysis to be done "later" may spend several hours in lab taking data totally unsuited to calculation of an accurate result. The student who plans a strategy in advance, knowing what must be done to obtain the desired accuracy, will spend lab time more efficiently, and obtain better results.
8.2 LINEAR RELATIONS
The simplest curve fitting problem is that of fitting a straight line to a set of data, as illustrated in Fig. 7.4. The problem is to find the slope of the line and its x and y intercepts. Two simpler cases frequently occur. (1) The line may be known to be horizontal and only the y intercept is required. (2) The intercepts may be of no interest and only the slope needs to be calculated.
The methods for fitting linear relations are of great importance because nonlinear problems may often be reduced to linear ones by an appropriate change of variable. Thus the relation Y = bx2 may be converted to the linear relation Y = bQ by letting Q = x2 or it could be converted to log Y = 2 log x + log b, and then to A = 2B + C by letting A = log Y, B = log x and C = log b.
(1) HORIZONTAL LINE. This case requires only a simple average of the data values. The average of N different quantities Qi is
| [8-1] |
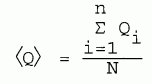 |
This method gives equal weight to each Qi. If the experimenter has knowledge that the individual data values are not equally reliable, this average will not give the best average value.
WEIGHTINGS. Suppose the experimenter has independent means for assigning an uncertainty to each data value. A graph of such data would have error bars of various sizes on each the data points. In taking an average it is desirable to have the least accurate data values influence the result the least. This can be done by assigning weightings to each piece of data, giving the greatest weight to the most accurate data. Then the weighted average can be calculated
| [8-2] |
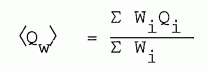 |
The summations are from i=1 to n.
In an elementary treatment of errors, the weighting factor Wi might simply be chosen to be the reciprocal of the error in Qi (whatever measure of error were being used). But if you want to obtain an average consistent with the least squares criterion (presented later in this chapter) the weighting factor must be taken to be the reciprocal of the square of the standard deviation.
(2) SLOPE OF A STRAIGHT LINE. We now consider the case where only the slope of a straight line is required, there being no need to calculate the intercepts.
SUCCESSIVE DIFFERENCES: It might seem that the problem could be solved by simply calculating the average slope of the line, that is by finding the slope between adjacent pairs of data points, then averaging all such slopes.
Consider, for example, a case where the data points are equally spaced along the x-axis, with spacing L, and the y values are a, b, c, d, e, f, g, and h. The slope in the first interval is given by (b-a)/L, and the average slope is
| [8-3] |
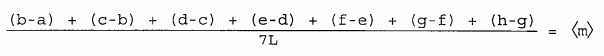 |
But notice that intermediate data points in the numerator cancel out and the equation reduces to
| [8-4] |
Only the first and last data points contributed to the average. The result is merely the slope of the line between points a and h. This probably is not the best fit line, and the effort of taking the other data points, and "calculating" with them, is wasted. A better calculation method is needed, one in which all the data contributes to the average.
THE METHOD OF DIFFERENCES avoids the difficulty mentioned above. To apply this method, first divide the data points into two equal groups (a, b, c, d) and (e, f, g, h). Then calculate slopes between the first points of each group, the second points, and so on, then average these slopes:
| [8-5] |
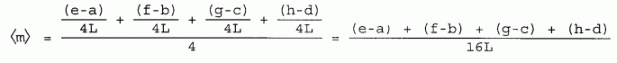 |
The intermediate readings do not cancel out of this equation.
WEIGHTED SUCCESSIVE DIFFERENCES: The successive differences method can be modified in such a way that intermediate data points do not cancel out, and the slope obtained is in fact the best fit. In effect, the method applies weightings to the successive differences, then averages them. the formula for the average slope of the line y = mx + b is:
| [8-6] |
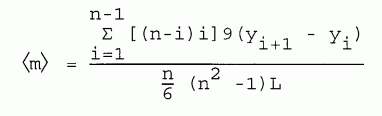 |
where n is the number of data points yi, and L = xi+1 - xi. The factor (n-i)i weights the points most heavily for the intermediate values of i and least for the smallest and largest values of i. For 7 data points, the weighting factors are 6/56, 10/56, 12/56, 10/56, and 6/56. This equation applies only to the case where the interval between values of x is constant. This formula is easier to calculate than the least squares formulae, and is well suited to computer solution. It is, in fact, equivalent to and derivable from the least squares derived slope.
(3) THE METHOD OF LEAST SQUARES. Legendre, in 1806, stated the principle of least squares for determining the best curve to fit a set of data. The principle asserts that the best curve is the one for which the sum of the squares of the deviations of the data points from the curve is smallest. To illustrate, suppose we have a set of n data values of y and x, such that to each xi there is a corresponding value yi. Furthermore, assume the errors are primarily in the yi, so the xi are assumed error free. If we choose a curve to approximate this data, it will not pass through each point. There will be a deviation (Dy)i in each point. The least squares criterion says that of all the possible curves one might choose, the "best" one is that for which
| [8-7] |
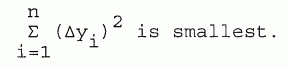 |
The reader may see in the formulation of this rule a hint as to why it is intimately connected with the standard deviation as a measure of error.
It might seem that the application of the rule to curve fitting would be difficult, if not impossible, for there are an infinity of possible curves to test! But one usually has a good idea in advance whether the best curve should be straight, parabolic, exponential or whatever, so all that remains is to determine its parameters. It is worth remarking that if there n parameters to determine, there must be at least n data points--preferably quite a few more than n to get a better fit.
Furthermore the methods of calculus allow the derivation of standard formulae for the parameters. We now state these formula without proof, for the straight line case.
Let the data points be (xi,yi) where i = 1, 2, ... n. We want to fit a straight line Y = mx + b to this data. (Upper case Y is used here, because values of Yi obtained from the formula for the fitted curve will not in general be the same as the data points yi). The slope of the line is given by
| [8-8] |
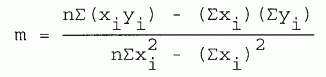 |
the summations being over i from 1 to n. The y intercept is given by
| [8-9] |
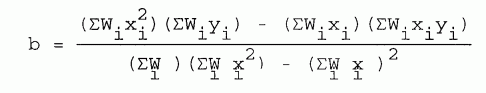 |
Notice that the denominators are the same in Eq. 8-7 and 8-8. They need only be calculated once.
The standard deviations of the slope and the intercept may also be found.
The standard deviation of the y intercept is
| [8-10] |
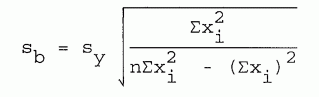 |
sy is the standard deviation of the individual data values from the fitted line, given by
| [8-11] |
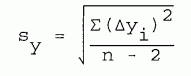 |
Dyi represents the deviation of yi from the fitted line and n is the number of data points.
The standard deviation in the slope is given by
| [8-12] |
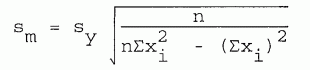 |
(4) WEIGHTED LEAST SQUARES. If the data points have different standard deviations, si, and we define weighting factors
| [8-13] |
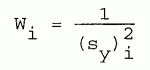 |
the least squares curve fit equations become
| [8-14, 15] |
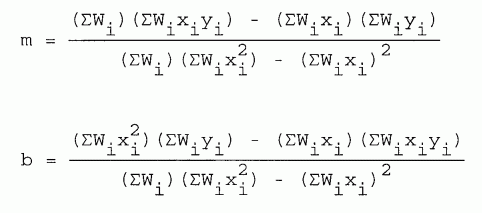 |
8.3 EXERCISES
(8.1) Write a compact formula for the successive differences method, using the summation symbol, and compare it with the formula for the weighted successive differences method.
(8.2) An experiment gives the data:
X Y 12 4.5 13 10.0 14 19.0 15 25.5 16 37.0 17 44.0 18 49.0 19 53.0 20 61.5
Find the slope of this straight line by the method of differences. An electronic calculator or computer is very desirable for these lengthy calculations.
(8.3) Use the least squares formulae on the data of problem 2 to find all parameters: slope, y intercept, and x intercept. The y values have a standard deviation of 0.5 units. Calculate the standard deviations of the slope and of the y intercept.
(8.4) Write and execute a BASIC or FORTRAN or PASCAL computer program to do the calculations of problem 3. Try to make the input routine general enough so you could use the program on any size set of data you might obtain in lab.
8.4 NONLINEAR RELATIONS The least squares principle may be extended to the problem of fitting a polynomial relation, and equations corresponding to (8-8) through (8-11) may be derived. Consult more advanced references for this. Since a very large class of relations may be approximated by polynomials, this approach has a wide utility, but in many specific cases other methods are simpler.
Another approach is to transform the relation by an appropriate change of variable, so it is in the form of a linear relation. This, in effect, straightens out the curve. This procedure is often used in graphical curve fitting, by plotting the data on special graph paper with non linear scales, such as log, log-log, polar or other types of graph paper as described in chapter 7. Carrying the graph analogy a bit further, note that if the original curve had error bars, they too will transform when the curve is "straightened out," and this will change the weighting factors.
EXAMPLE: EXPONENTIAL RELATION: Consider a set of data A vs. C assumed to satisfy the relation A = BC(2q), which can be straightened by plotting on log paper, in effect transforming the relation to
log A = log B + 2q log C
This is of the form Y = mx + b if we use the transformation relations
y = log A b = log B x = log C m = 2q
This can be fitted by equations (8-7) through (8-10) if c is an independent parameter of negligible error, and the error is all in the variable A.
But if the standard deviations of the Ai are (SA)i, the standard deviations of the transformed variable Yi will become log (SA)i. Then the weightings of the Yi will be
1 (W ) = ——————————— y i 2 [log(S ) ] A i
The analysis now proceeds as for a straight line fit, and values of m and b are determined. Transforming back by Eqs. (8-17) gives values for B and q.
© 1996, 2004 by Donald E. Simanek.